
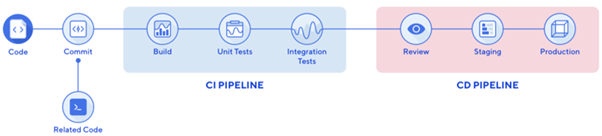
CI/CD is a method to frequently deliver apps to customers by introducing automation into the stages of app development. When changing code is routine, development cycles are more frequent, meaningful and faster. Continuous integration (CI) and continuous delivery (CD) embody a culture, set of operating principles, and collection of practices that enable application development teams to deliver code changes more frequently and reliably.
The technical objective of CI is to establish a consistent and automated way to build, package and test applications. With this consistent integration process in place, development teams are more likely to commit code changes with greater frequency, which in turn leads to better software quality.
Continuous delivery picks up where continuous integration ends. CD automates the delivery of applications to selected infrastructure environments. Most teams work with multiple environments other than the production, such as development and testing environments, and CD ensures there is an automated way to push code changes to them. Though the writing of code still requires human intervention, the building and deployment of applications can be automated. Automated CI-CD pipelines remove manual errors, provide standardized feedback loops to developers, and enable fast product iterations.
Thanks to Kent Beck and Ron Jeffries; Extreme Programming came into existence. With that, Continuous Integration and Continuous Delivery, today became salt equivalent in every modern software cookbook. As much as the companies across the globe want to master the art of constant production of usable software, most of them are failing to put together an effective pipeline. From ensuring the team isn’t getting easily distracted from one issue to another without completely solving the earlier- to automating all the deployments, there are many things to keep an eye on. Constant building, packaging, continuous testing and deploying can work as a beautiful symphony if it is orchestrated well. Here are some essentials and opulence ingredients (capabilities) every CI-CD pipeline must have to minimize failures and accelerate productivity.
Recipe for Successful CI/CD
Testing
The ultimate goal of software testing is to evaluate every unit or component of software compliance with the specified needs. Before I even start to emphasize how important to have strong fool-proof Testing practices in place, let me shift my spotlight a little towards a very important yet often overlooked practice called ‘checking the code quality before testing’. Unit tests help the developers to ensure new code works in isolation.
Examining the functional as well as structural quality to identify bugs, coverage, vulnerabilities and code smells can make dramatic improvements in software’s business value. This requires Dynamic as well as Static Program Analysis, preferably in real-time. While tools like HCL’s AppScan, Gcov, Prism, etc., handle Dynamic Analysis covering security, code coverage, runtime threading errors and any other behaviors that can lead to performance degradations; there are many open-source platforms that can continuously inspect code quality through Static Program Analysis. Our personal favorite is Sonarcube. Since all these tools come with pretty self-descriptive dashboards, it’ll be great if one can set out a little time mapping the development process, which gives you data that is exclusive and actionable.
Now that we are all on the same page about Code Quality Analysis, the actual Testing will be a piece of cake (metaphorically). I mean checking quality software for bugs isn’t as complex. All of us run Unit, Integration, System, Acceptance and Regression tests each time there is a new piece of code. But, running them in various environments and checking distinct areas like platform and network connectivity is essential too.
Packaging
Just because you are deploying often, doesn’t mean you can deploy random pieces of code. It goes without saying, the code has to be packaged well. Designing a deployable artifact is the prime objective of your CI part of the pipeline. It could be your source code or a docker container – whether it is a .war or .jar file; it is important to have confidence in your packaged code that you can deploy it in any environment from test to production. Tools like Groovy Scripts can wrap the code, bundle it and push it to the required environment. Orchestration engines like Ansible can automate deployments which will take out a good bit of potential human error.
Security
The rise of DevOps has certainly transformed the landscape of software production. In parallel to the methodologies, the vulnerabilities that come with them have become stronger too. To be able to deliver often without compromising on the value, infusing security scanning at every level of SDLC is the only way. And I don’t just mean Shift Left. I mean Code and Artifactory scanning, composition analysis, looping in feedback… Ultimately move towards DevSecOps.
It is advisable to break down the deployment into smaller segments and gives attention to each – one at a time. Don’t completely depend on the Ops team or Infosec team for security scanning. Developers must be empowered to own the security concerns and should have access to tools to fix them at the inceptive stages. Enabling Test Automation promotes shorter feedback loops. There are both commercial and open-source tools to handle Static, Dynamic and Interactive Security Testing. Taking advantage of those tools would cover both codebase and runtime vulnerabilities. Cloud platforms like Jenkins, git-secrets and AWS config verify the sensitive information in repositories and blocks commits when rules are violated before the code is pushed. As they say, your tests may come clean but, your code isn’t production-ready unless it is secure.
Automating Deployments
They automate code builds, testing, staging, and even roll-backs. But for some reason, many teams still prefer to handle deployments to production environments manually. A good CI-CD pipeline is supposed to have minimum manual intervention and run automatically. That affects the overall Turnover Time impressively. We could never emphasize more about exploiting the cloud-native landscape. Segmenting the applications into decoupled microservices, packaging each part into its own container, and dynamically orchestrating those containers will optimize resource utilization. We find Kubernetes more efficient than any other platform to automate the deployment, scaling, and management of containerised applications. Tools like this can help Ops teams to schedule workloads and allow container pods to be deployed at scale over multi-cloud environments. Finding one tool to fix everything might be a challenge but there is no lack of open-source tools in the market that can be customized to fit the requirement.
Post-Deployment Inspections
Even after having multiple check gates and strongest testing methodologies; the build might fail you at an aspect that you least suspected. Only Sanity checking can save you from failure. Rigorous smoke, performance and functionality tests must be run at periodical intervals. As the application grows bigger and the number of services may increase, rapid performance setbacks may arise, new endpoints may come into existence to challenge the monitoring, the root-cause analysis will keep getting longer. As there are many open-source tools involved in the Continuous Deployment pipeline, controlling their data streams, mapping and tracing the instrument code gets difficult. Thus, human dependency increases.
Establish clear communication between the services, tools, APIs and aim at the synchronization of data. Always ensure your HTTP call returns with a 2xx status code. Continuous Monitoring tools like Nagios and AppDynamics can come to your rescue. Defining alert rules, configuring thresholds and policies will save the team efforts from unforeseen obstructions. The tools mentioned above can also be configured to alert Infrastructure and application performance problems.
Auto-Healing
By now, we’ve established the importance of full-stack monitoring in modern delivery pipelines. Knowing the hazard without being able to act on it immediately is as good as not knowing it at all. Whenever a Health check identifies a failed deployment or a performance deficiency, or when a hardware defect is detected, an ideal Continuous Delivery - Continuous Integration pipeline will have a mechanism that can trigger an automated rollback or recovery. Having features such as – Auto-scaling, killing previous/timed-out sessions when there is an excess load on the server, creating webhooks to rollback are some of the low-hanging fruits.
No automated testing suit in the world guarantees a cakewalk in software production. So, learning from the logs, detecting root cause and having the best possible alternative to save the system from ultimate failure is necessary. Applying AI into the Digital Performance can’t be done overnight. It requires expertise in different environments, technologies, frameworks and patterns studies. You get better as you learn, try, fail and learn again.
Metrics for Successful CI-CD
Bringing the development and operation teams together, collectively investing efforts to achieve the state of continuous integration, deployment, and delivery – all is good as long as there is consistency in improvement. And the only way to ensure is to have metrics in place. While there are many areas of the pipeline that can be measured and made better (like Failed Deployments, number of fixed bugs, number of user stories that are closed before sprint release, etc); the key metrics of DevOps are the non-negotiable measurements of improvement. They are: Deployment Frequency, Lead Time, Error Rate, and Mean Time to Recovery. Tools like Jira can track and report the illustrated results. Another metric that can help the scale of improvement is ‘Usage of a feature’. Tracking the usage of a new release for the first few months tells a lot about the user priorities and behavior which can help building the upcoming features.
Having all the ingredients won’t guarantee the success of a recipe unless you know the right ratio and the right timing to introduce each into the pipeline. Understanding that data is the lifeblood for successful CI/CD pipeline is essential. As we always say, it is all about the culture. A culture of innovation and exploration. A culture of failing and learning from it. A culture that stresses enough on team-work and empowering each other. Thanks to that culture, we have whipped some amazing solutions for our clients since our inception. We’d love to share our learning with you. Write us about your toughest CI-CD challenges and we just might have the answer for you. info@qentelli.com

